Mamba
我们假设在时间步 t 的输入为 xt∈RD,序列长度为 L。在 Mamba 中,我们将 xt 的每一维看做一个独立变化的函数。我们用额外的 N 维向量来作为隐状态 h∈RN,用于近似这个函数。我们假设 x 某一维随 t 变化的函数为 u:R↦R
h′(t)y(t)=Ah(t)+Bu(t)=Ch(t)
其中 A=diag(α1,⋯,αH)∈RN×N,B,C∈RN。
Zero-Order Hold 假设 ZOH 假设在两个离散的采样点之间,u(t) 保持不变:
u(t)=uk ,if t∈(tk−1,tk]
离散化 将两端乘上 e−At 有
e−Ath′(t)e−Ath′(t)−e−AtAh(t)dtd(e−Ath(t))h(t)=e−AtAh(t)+e−AtBu(t)=e−AtBu(t)=e−AtBu(t)=eAt(C+∫e−AτBu(τ)dτ)
分别取 t=tk−1,tk,那么有:
hk−1hk=eAtk−1(C+∫0tk−1e−AτBu(τ)dτ)=eAtk(C+∫0tke−AτBu(τ)dτ)=eA(tk−tk−1)⋅eAtk−1(C+∫0tk−1e−AτBu(τ)dτ) +eAtk∫tk−1tke−AτBu(τ)dτ=eA(tk−tk−1)hk−1+eAtk∫tk−1tke−AτBu(τ)dτ
令 Δk=tk−tk−1,那么有
hk=eAΔhk−1+eAtk(∫tk−1tke−Aτdτ)Buk=eAΔhk−1+eAtkA−1(e−Atk−1−e−Atk)Buk=eAΔhk−1+A−1(eAΔ−I)Buk
因此有
Aˉ=eΔA,Bˉ=(ΔA)−1(eΔA−I)ΔB
Selective State Space Model
Mamba 不采用常数的 B, C 矩阵,而是将 B, C 改为输出 xt 相关,通过一次投影计算。对于输入 xt 每一维度,均使用一个独立的步长,由输入 xt 投影并加上偏置得到。由于 B 也是一个与 t 有关的变量,上面的积分部分 ∫tk−1tke−AτBu(τ)dτ 直接用右端的函数值近似为一个矩形,Mamba 实际采用的离散化方式是
ht≈eΔtAtht−1+ΔtBtxt
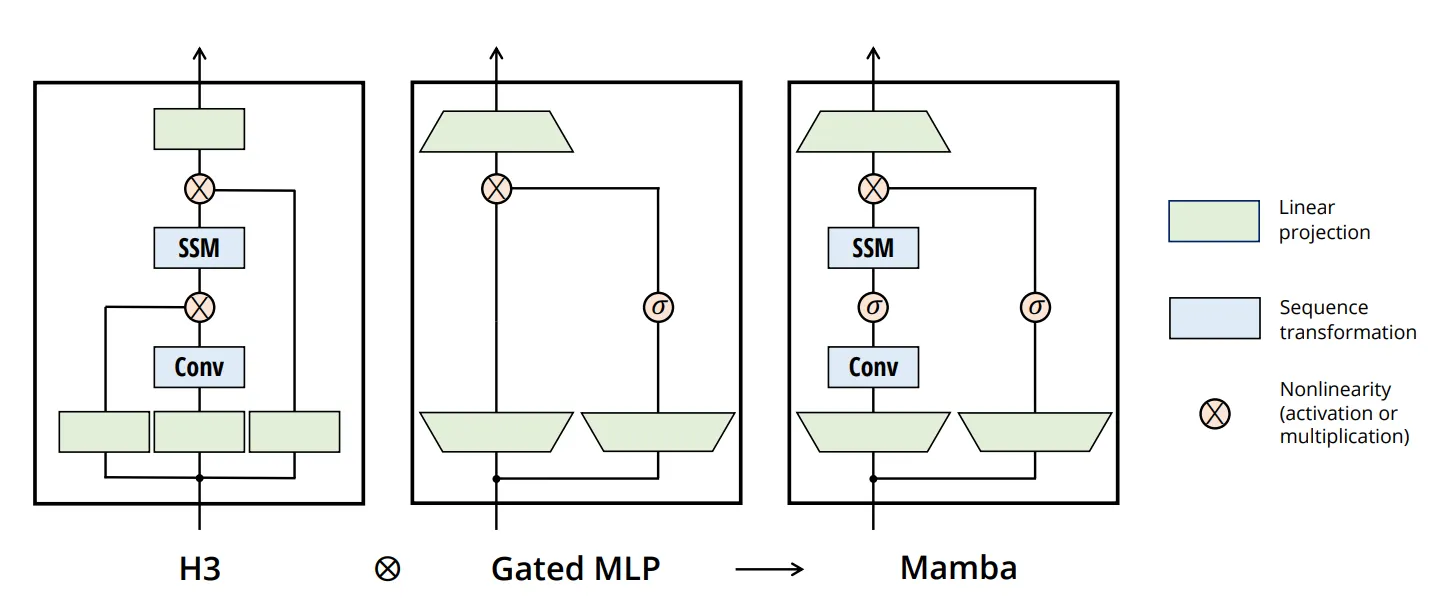
在架构上,Mamba 结合了前序工作和 Gated MLP。在 SSM 变换前做了一个局部的 Casual conv,剩下的话就是让 FFN 包在外面了。
我们从 query-key attetnion 的视角来看一下 Mamba 的 SSM 在做什么。将 Mamba 输入 xt 的每个维度 d 看做 attention 中独立的 head,令
qt=WCxt∈RD,kt=WBxt∈RD,vt=(xt)d∈R
这个 head 中,对于时间步 t 的输出可看做:
yt=qtTht=qtTi=1∑t(j=i+1∏tAˉi)k~iviT
其中 k~i=(ΔAi)−1(eΔAi−I)Δki∈RD。其实 query-key attention 的视角来看 mamba 的问题,感觉还是挺明显的,一个是它的 value dim 只有 1,另一个是它不同的 head 的 query 完全一样,它不同 head 间的 value 仅需要通过和某个向量做 Hadamard 积就可以转换。
Mamba-2
Mamba-2 主要的改进是由于 Mamba 的并行扫描对 GPU 的利用率仍然不如矩阵乘法。因此 Mamba-2 为了使用更多的矩阵乘法运算,将 head 的数量从 D 削减到 Transformer 常用的一个维度。除此之外对 State Space Model,稍作修改,把它从输入 R 改为到 R1×P 的(其中 P 为 head dim)。
h′(t)y(t)=ath(t)+BTu(t)=Ch(t)
其中 B,C∈R1×N,h(t)∈RN×P。其实等价于将每一维用相同的参数 (A,B,C) 看度看做一个 SSM。所以其实离散化的过程几乎完全一样。
我们用 query-key attention 的方式重写一下:
qtktvt=Ct=WCxt,=Bˉt=at−1(eΔat−1)WBxt,=xt
中间省去的 ∏iai 可以看做是与另一个矩阵 L 做 Hadamard 积:
YLij=(L⊙QKT)V=⎩⎪⎪⎨⎪⎪⎧∏k=j+1iak10,i>j,i=j,i<j
为了能高效训练,Mamba-2 结合分块,对于块内采用矩阵乘法进行计算,对于块间仍然采用并行扫描,但是由于并行扫描的序列长度减少了 chunk size 倍,因此效率更高。
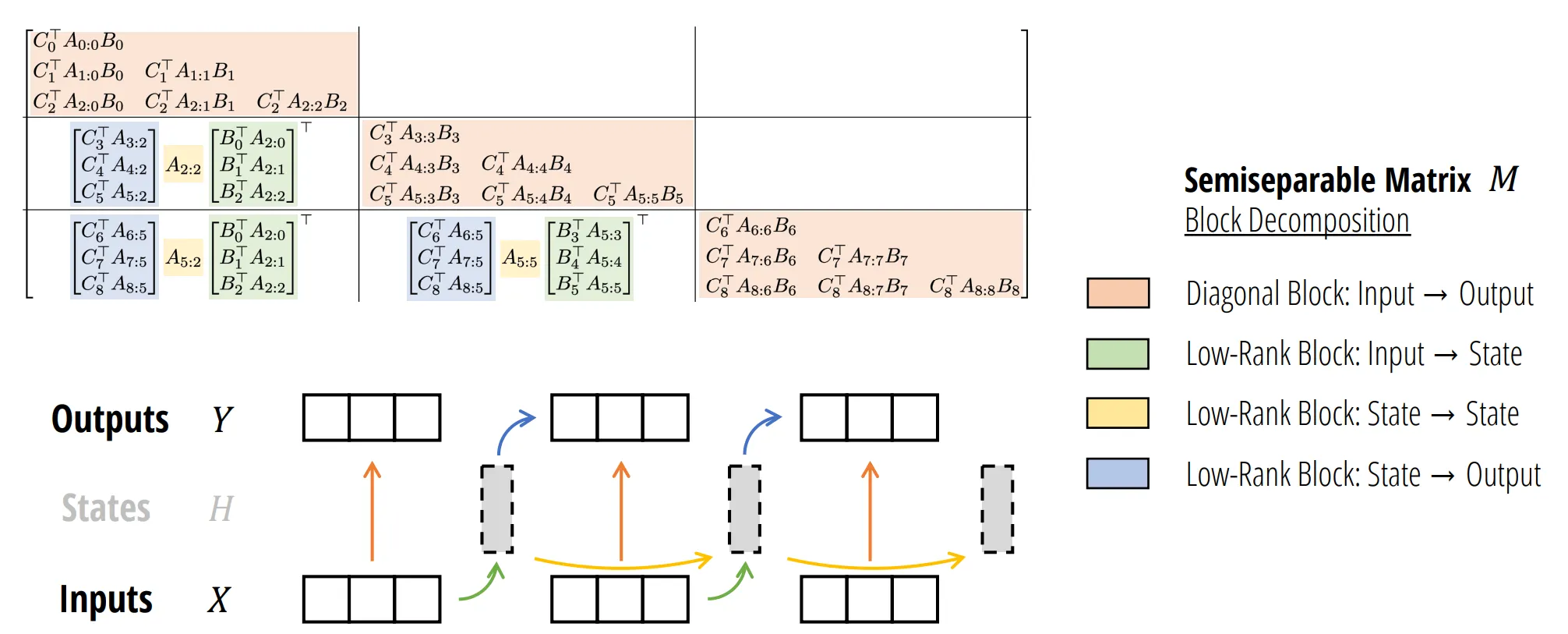
Mamba-3
Mamba-3 主要从 3 个方面进行改进 Mamba-2。
Trapezoidal Discretization
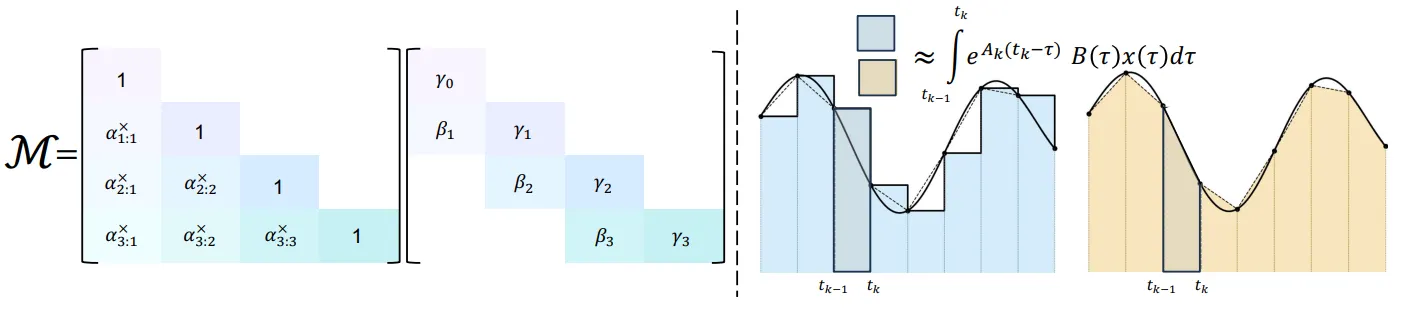
在 Mamba 和 Mamba-2 中,采用 Euler 积分,用右端的函数值近似为一个矩形,这在一个时间步内的积分会有 O(Δ2) 的误差。在 Mamba-3 中则是采用推广的 Trapezoidal 积分,用积分两端的结果进行线性插值:
hk=eΔkAkhk−1+eAtk∫tk−1tke−AτB(τ)u(τ)dτ=eΔkAkhk−1+(1−λk)ΔkeΔkAkBk−1uk−1+λkBkuk
它对结构权重矩阵 L 的影响相当于乘上了一个特殊的矩阵:
⎣⎢⎢⎢⎢⎢⎢⎡γ0(γ0α1+β1)α2(γ0α1+β1)⋮αT⋯2(γ0α1+β1)⋱⋯γT⎦⎥⎥⎥⎥⎥⎥⎤=⎣⎢⎢⎢⎢⎢⎢⎡1α1α2α1⋮αT⋯11⋱⋯1⎦⎥⎥⎥⎥⎥⎥⎤⎣⎢⎢⎢⎢⎢⎢⎡γ0β10⋮0γ2⋱⋯γT⎦⎥⎥⎥⎥⎥⎥⎤.
Complex-Valued SSMs
在 Mamba 以及 Mamba-2 中,SSM 模型中的 A 采用实对角矩阵,这样不能表示复数的特征值。为了解决这一问题,Mamba-3 将 SSM 推广到复数域:
h˙(t)=Diag(A(t)+iθ(t))h(t)+(B(t)+iB^(t))x(t),y(t)=Re((C(t)+iC^(t))⊤h(t)),
其中 h(t)∈CN/2,θ(t),B(t),B^(t),C(t),C^(t)∈RN/2,x(t),A(t)∈R。可以证明在 Euler 离散化下有
htyt=eΔtAtRtht−1+ΔtBtxt,=Ct⊤ht
其中 Bt=[BtB^t]∈RN,Ct=[Ct−C^t]∈RN。以及旋转矩阵:
Rt=Block({R(Δtθt[i])}i=1N/2)∈RN×N,R(Θ)=[cos(Θ)sin(Θ)−sin(Θ)cos(Θ)]
对于 Rt 的计算,可以采用和 RoPE 相同的 Trick 将其拆成两段前缀积的乘积,分到 query 和 key 的计算里面:
ht=eΔtAtht−1+(i=0∏tRi⊤)Btxt,yt=((i=0∏tRi⊤)Ct)⊤ht

在不改变的参数情况下,增加隐藏层的维度,然后根据原来的维度分为 r 个组,每个组采用相同的参数独立计算。由于解码时的算术强度增加,从 Memory-bound 的操作变为了 Compute-bound,所以这样的改变不会显著增加 decode 的时间,但是能够提升模型的效果。
Architecture
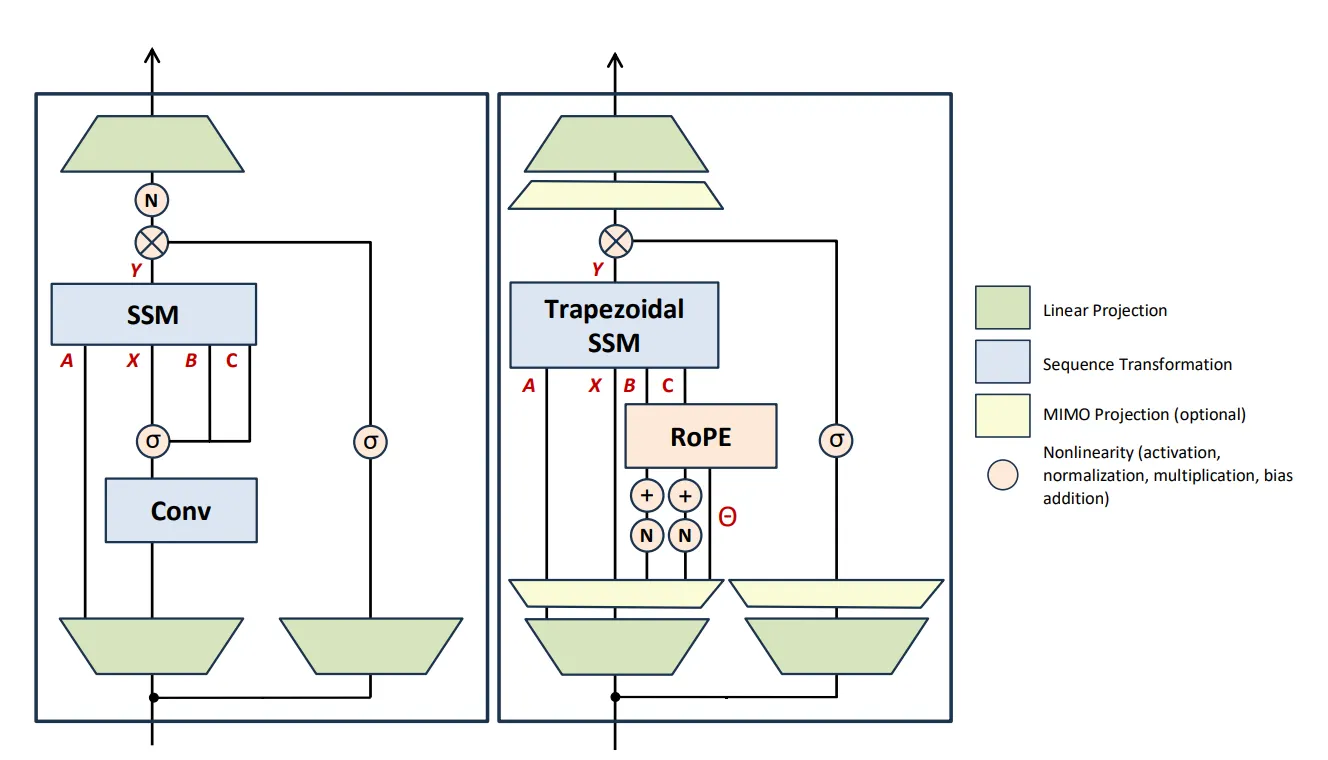
左图为 Mamba,右图为 Mamba-3。一个是移除了 Conv1d,另一个是在计算 B,C 时加入了归一化和 RoPE。以及新增了额外的 MIMO 投影的模块。
