
考虑做一个图像分类问题,但是有一点不一样:我们首先在数据集 上进行训练,接着我们在数据集上 上训练,由于 和 都非常地大,我们不能将数据集完全保存下来,所以不能反复遍历 的数据来训练,只能记录一些东西,然后将 丢弃,接着我们会在数据集 上训练,并保持类似的限制,以此内推,最终我们在数据集 上训练,接着我们将要在测试集上评估模型的性能。这样的问题称为持续学习(Continual Learning)。
Continual Learning 带来最大的问题是遗忘,如果我们不加任何外部干预,并且都在每个数据集上训练到收敛,那么模型学习到的数据分布是 所得到的数据分布。一种最极端的例子,考虑每个数据集的类别都不同,那么模型对于第一种类别的学习到的判定方式可能已经面目全非了。
较早的一些 Continual Learning 的解决方法是为每个类别记录一些有代表性的样本,在之后的训练中重放这些样本。但是对于图像数据的话,一张图片的大小也不小,当允许存放的样本很有限时,模型的性能会急剧下降。虽然有一些更多的方法,不过我是一点没学,可以看这篇综述。直接存放样本的效率并不高,因此可以在如何去存储知识上进行优化。
考虑在图像预测的过程,首先我们将输入图像 ,然后我们将图像通过 CNN 等神经网络将其编码为 ,接着通过分类器得到标签预测的概率分布 。
其实这里 相当于一个编码器,而我们实际处理的是完成下游的分类任务。而这样的事情在 CV 和 NLP 中非常常见,例如在 NLP 中,对于某个特定领域,我们会对大模型进行微调、或者通过 Prompt Tuning 去在某一个领域去达到更好的效果。
由于有论文证实基于 Prompt Tuning 相比直接进行微调效果更好。因此作者选择通过 Prompt Tuning 来将任务相关的信息 加入编码过程。所以主要的思路是:根据任务或者样本,由某个可训练模型给出 Prompt,接着将样本和 Prompt 提供给预训练好的模型,接着再通过 classifier 得到预测标签的概率分布。
Vision Transformer
在 CNN 设计时就已经存在两条归纳偏置:
- 局部性:相邻区域有相邻的特征
- 平移不变性:同样的物体,在不同的位置可以被相同的卷积核识别出来
因此 CNN 训练并不需要太多的数据。而 Transformer 没有这一些归纳偏置,因此需要用更多的数据去训练。ViT 这篇的工作便是去验证在大数据集下,Transform 也能在 CV 领域取得更好的效果。省流:我们用更多的钱更多的数据去训练了更大的模型,所以它 work。
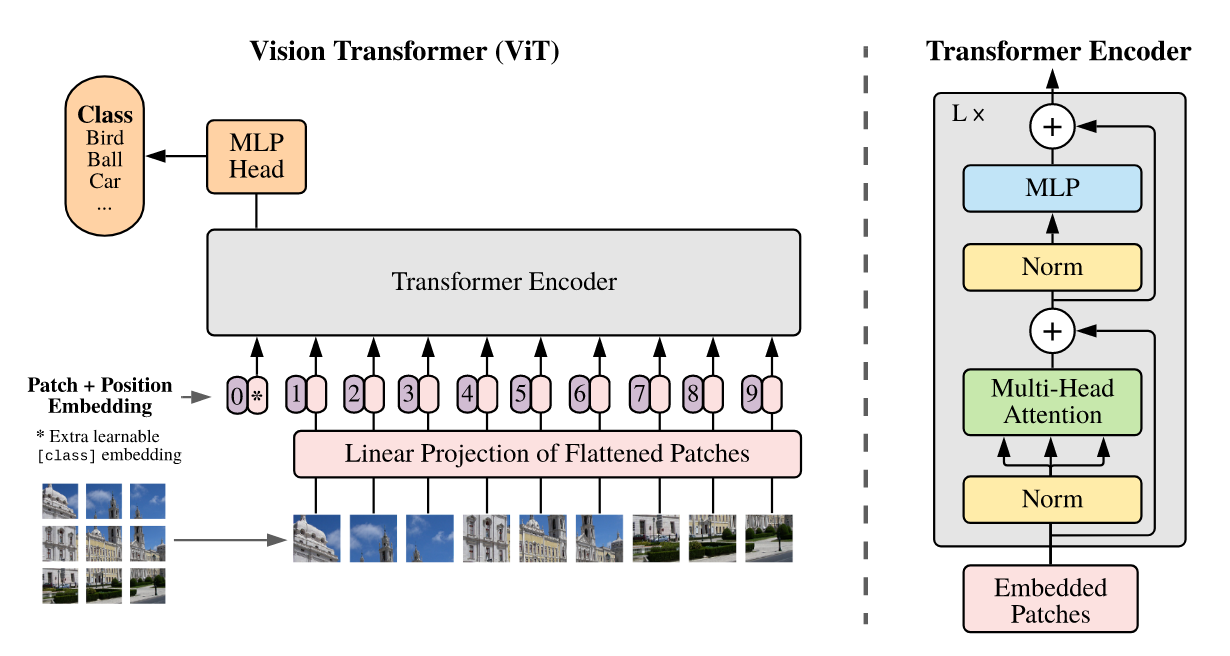
为了解决图像的像素非常多,直接展平会导致计算复杂度很高的问题,ViT 先将图片进行分块,然后对于每个 patch,通过连接然后展平,通过线性投影将它压缩成一个 token:
其中 是特殊 token [CLS] 的嵌入向量,最后分类的时候将这个特殊 token 学习到的隐向量作为图像的编码,在接入一个简单的 MLP 进行分类,这个做法来自于 NLP,打通 NLP 和 CV 壁垒,原文作者直接将它搬了过来。CV 领域做图像分类一般是通过全局平均池化得到图片的编码,不过作者发现它们两者效果相近,但是它们需要不同的学习率。
位置编码可以使用 1d 的位置编码,也可以使用 2d 的位置编码(将 中坐标分别编码然后拼接起来),也可以使用相对位置编码。作者通过实验发现它们的效果都差不多。
ViT 剩下的部分和 Transformer 完全相同,就不再赘述了。
Prompt Tuning
希望通过 Prompt Tuning 去指导 Transformer 使用预训练信息也带来一些关键性的问题:比如这个 Prompt 怎么来得到?一种简单的想法是基于每个任务去训练一组 Prompt。但是这样会直接带来一个问题:测试集用啥 Prompt?这种方法也会阻碍模型跨过不同任务去学习。
因此它其实应该一种类似于记忆的功能:模型能够逐步记住一些东西,并且根据需要进行查询。同时我希望这一段记忆能够记住很久以前的内容。
这部分的设计其实类似于 Nerual Turing Machine。我们有 片内存,它们构成 Prompt pool,每片存储 ,其中 是一个 维向量作为键,用于查询,而 为对应的 Prompt。对于一个输入我们将它首先在 Prompt pool 中查出相关的 prompt,将它作为提示信息把它和预处理后的输入一起提供给预训练的 Transformer 模型,接着再扔给 classifier 即可。
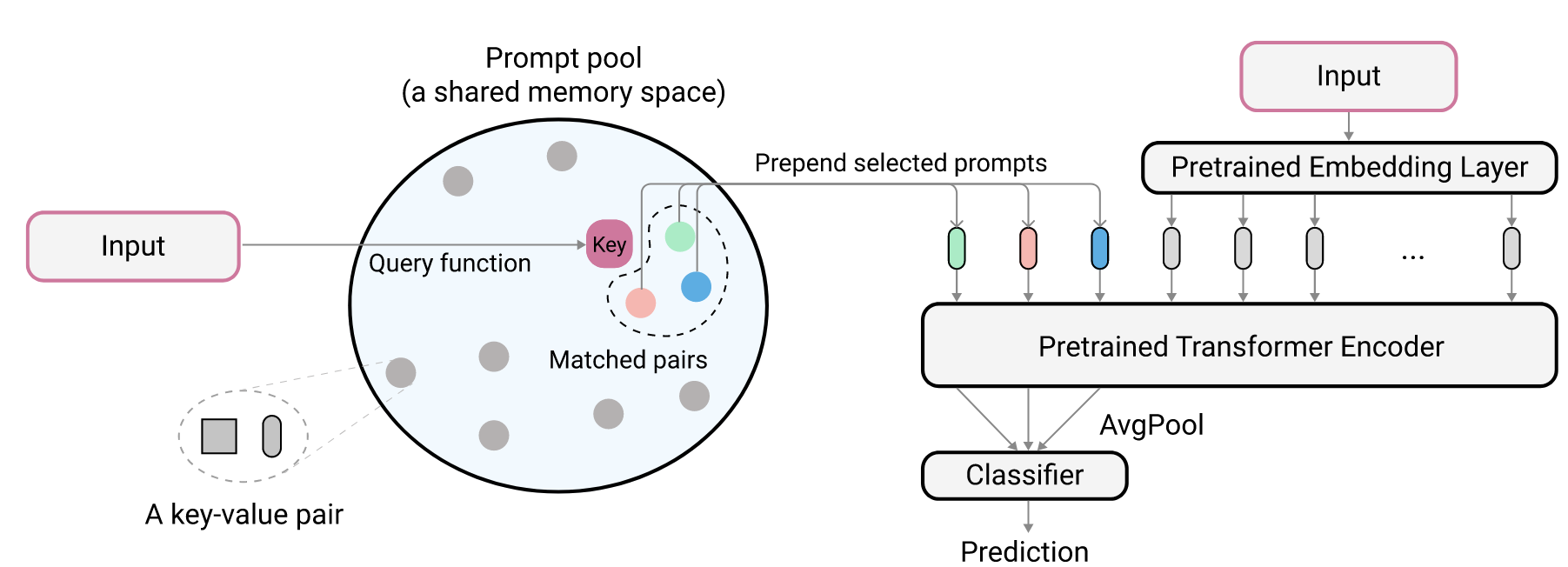
首先我们需要处理查询,类似于注意力机制,查询的时候我们需要一个查询的向量。我们容易用一个编码器对输入图像进行编码,然后得到查询向量 。接着选出 个键与查询向量余弦相似度最高的 prompt,接着将其提供给预训练模型。作者这里仍然使用 ViT 对其进行编码,将第一个 Token 设置为 [CLASS] 这个特殊的 token,然后将它的隐向量作为所需要的向量。
Optionally diversifying prompt-selection 当我们知道任务边界的时候,即我知道这个数据来自于 ,还是已经知道它来自于 ,可以借助这个来做进一步的优化:更充分地利用内存池。假设我们现在在 ,我们去统计在前 个任务上,每片内存被访问的频率 ,在选取时我们按照 最小的 片内存作为的 Prompt。其中 为某种距离度量,作者在这里使用的余弦距离。
优化目标
我们这里可训练的参数有: 以及 classifier 参数 。
第一部分是正常的分类的损失,第二部分是由于我们的内存片是通过余弦相似度选了部分出来,显然不能够直接反向传播去更新 ,因此我们希望选择的内存片的键向量和查询向量尽可能相似,便有了这一项。