
U-Net 主要改进 Ciresan 等人的做法中的两个缺点:效率低以及很难使用较大范围的局部信息,并同时继承其两项优点:对每个像素的类别进行预测,同时不需要大量的图片数据。
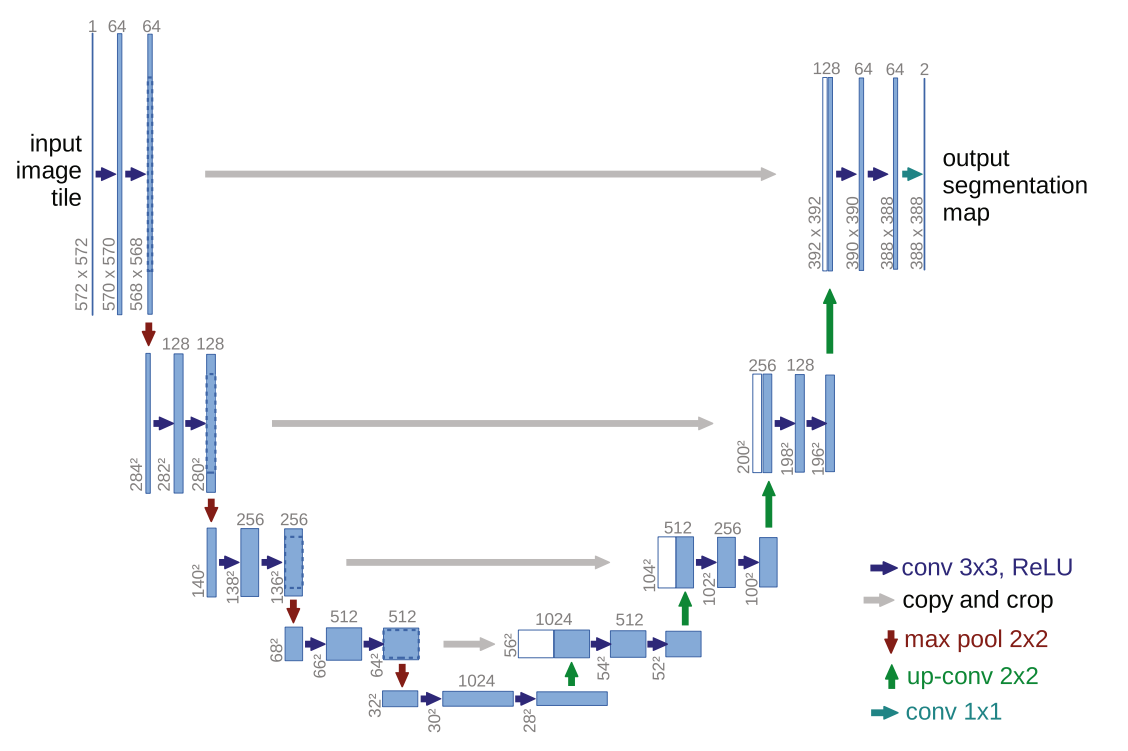
U-Net 的架构如下
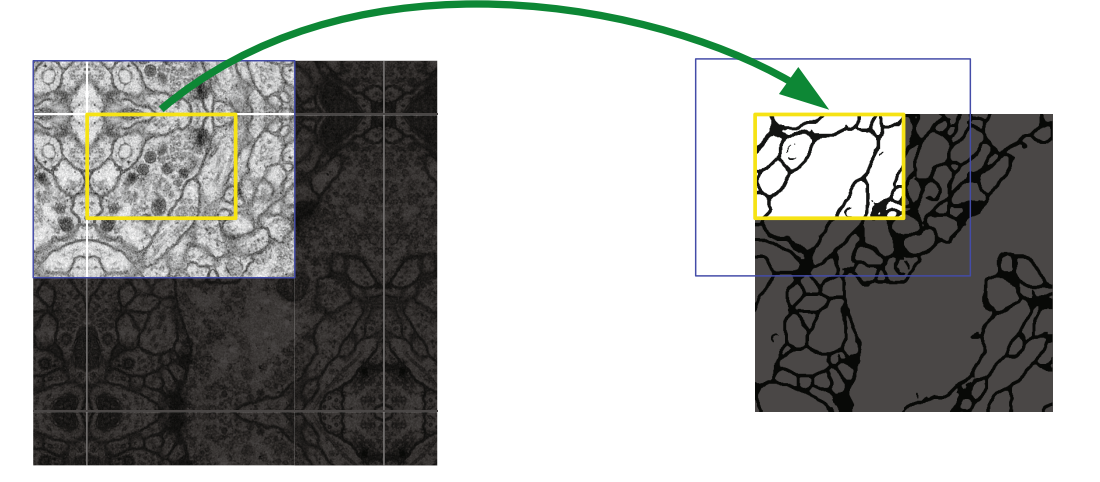
对于图像边缘进行识别时,在卷积层中使用 zero-padding 的效果并不好,因此 UNet 的处理方式是对于输入的图像将边缘通过镜像的方式进行填充:
在 U-Net 的架构中,左侧使用 conv 和 pooling 主要进行特征的提取。右侧则是将特征将与原始的网络进行融合,每一步首先将深层的特征进行上采样,然后与特征提取对应的网络进行拼接融合。由于 max pool 会丢失图像信息,这一步相当于是去融合深层特征和浅层的一些位置信息。
最后则是通过 2 个 1x1 卷积核再加上 softmax 操作生成每个像素每个类别的预测结果。
图像增广
图像增广在对训练图像进行一系列的随机变化之后,生成相似但不同的训练样本,从而扩大了训练集的规模。 此外,应用图像增广的原因是,随机改变训练样本可以减少模型对某些属性的依赖,从而提高模型的泛化能力。
常用的一些图像增广的方法有:
- 翻转图像
- 对图像进行放缩或者旋转
- 改变颜色:亮度、对比度、饱和度和色调
权重图与损失计算
U-Net 在训练的时候计算一个权重图,用于解决下面问题:
-
训练数据中,每个像素作为每种类别的概率不相等,对于类别概率越不均匀,我们赋予它更大的权重 。
-
两个细胞粘黏的时候,它们难以被区分出来。这一项权重通过下面的方式来计算:
其中 和 为参数。 分别表示 到最近的边界距离和第二近的边界的距离。
那么最终的权重为 。
在计算损失的时候,设在 处的交叉熵损失为 。那么最终损失为
复现
在 VOC2012 的语义分割数据集上训练 UNet。在 loss 函数中,为每个非背景元素以及背景元素额外赋予权重,使得非背景元素和背景元素的总权重各占一半。
初始的 lr 设为 1e-4,在 google colab 上训练了 90 min,loss 降低到了 1.46 左右,效果如下:

感觉 UNet 做多分类的效果有点不太行?

踩坑
- 这个问题上 SGD 需要的初始 lr 比 Adam 要高很多,用 SGD 的话 lr 设 0.1,最开始用 Adam 但是 lr 设在 1e-2, 1e-3 ,loss 当时也有点小问题,然后就跑出来全黑。