
LangChain 是一个框架,它旨在帮助开发人员更好地利用语言模型来构建应用。大语言模型对自然语言有一定理解能力,但是其逻辑、计算和搜索能力等方面能力有限,同时训练结束后模型便固定下来,对于新产生的各种信息便不会被模型学习。LangChain 的想法在大模型的基础上,集成一些工具。比如我想要解决一个问题,大模型可以通过工具来获取一些信息,然后再根据这些工具得到的信息由大模型生成最终的答案。
下面随便瞎记一些东西,应该会不定期更新。如果下面看到什么地方感觉缺了很多,完全不能用那种,那应该是我暂时用不到这方面内容,所以没学。
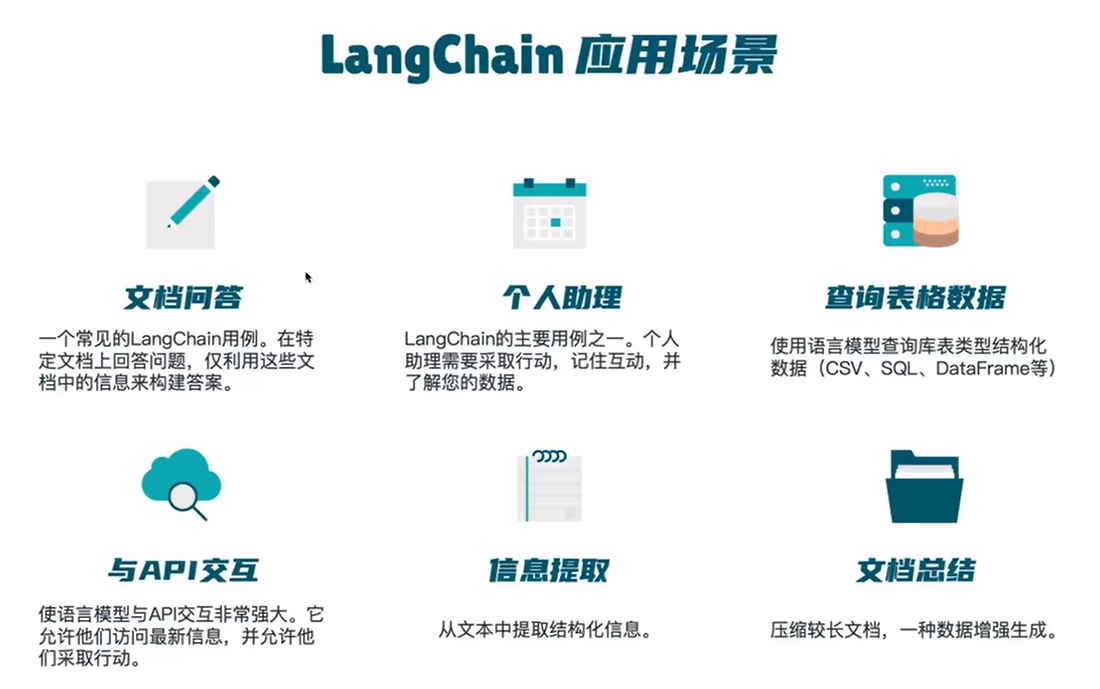
一些应用的流程
基于本地知识库问答
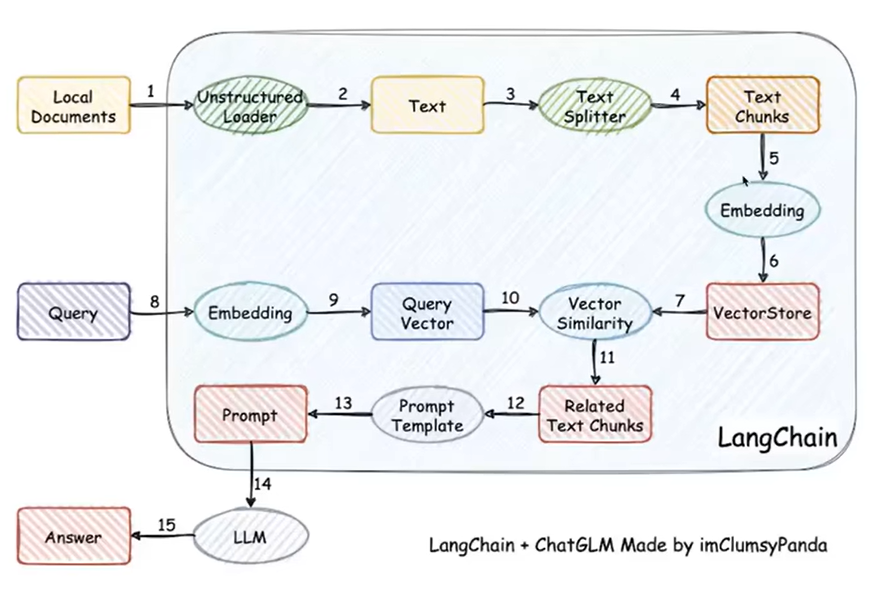
它的想法是将本地文本库读入,由于文本很长,所以将其拆分为一小段一小段的,接着通过嵌入将其转化为语义向量存储,这个便是知识库。对于查询操作,经过相同的嵌入处理将其转化为查询向量,接着通过向量的相似度查询到最相关的语段,将这些语段添加上下文,接着再进行一些去重,再由这些信息生成 prompt,将其输入到大语言模型(LLM)中。这一步如下图所示:
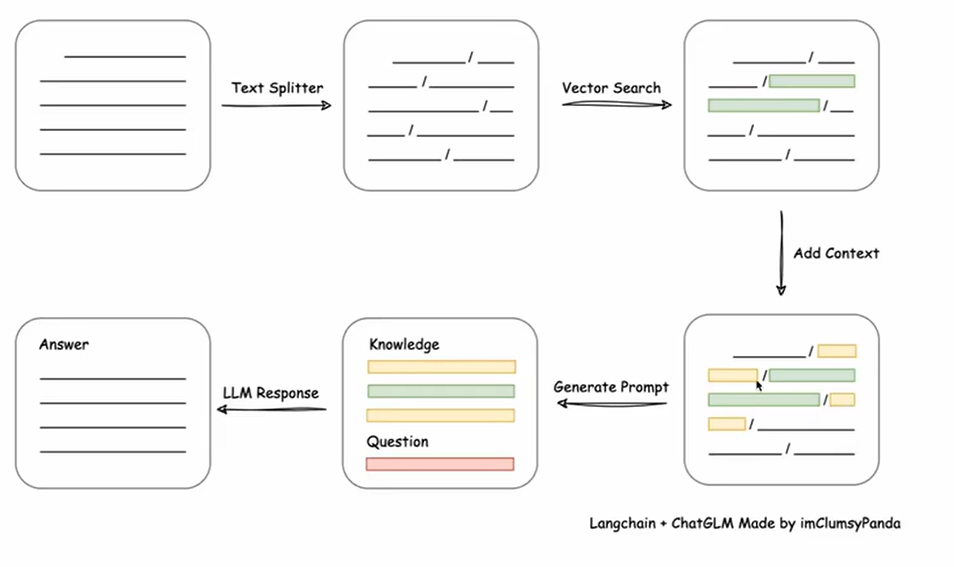
这些过程在 LangChain 中都有实现。
关于 LangChain 的使用
部署大模型
虽然自己电脑显存很小,但是发现可以嫖 Google colab 有 15G 显存的 GPU。
在左上角 代码执行程序 里面 更改运行时类型 里面选择有 GPU 的就能开用了。如果没有这个选项栏,可能是和我一样折叠了,点一下右上角的箭头就可以看到了。
不氪金的话,Google 不给你终端,但是在 jupyter 里面语句最前面加 % 和 ! 可以执行 bash 脚本。具体区别目前还不是太清楚,但改当前目录的时候要用 %。
Colab 的服务器不会保存你的任何文件,连接结束后,新产生的各种文件都会丢失。但是可以挂载 Google 云端硬盘,直接对 Google 云盘内的东西进行操作。挂载 Google 硬盘后,可以用下面命令切换到 Google 云端硬盘的根目录:
1 | %cd '/content/drive/MyDrive/' |
接着可以下载大模型。这里用 chatglm2-6b-int4 为例,新建一个目录,切换到这个目录下,然后用下面代码从 HuggingFace 上下载模型下来。
1 | import os |
接着通过下面的代码可以导入大模型:
1 | tokenizer = AutoTokenizer.from_pretrained("data/pretrained_models/chatglm2-6b-int4", trust_remote_code=True) |
虽然不太清楚 .half() 是做什么用的,但之前没加的时候报过奇奇怪怪的错误。
要在 LangChain 中使用的话需要用 langchain.llms.base.LLM 封装一下。
运行流程
这里记一下 LangChain 中 ZeroShotAgent 大致的一个运行流程。Agent 做的事就是连接 LLM 和工具,当然工具可能会有查询数据库之类,ZeroShotAgent 用的是 ReAct 框架。不想看论文的话,这里有一个视频介绍它的想法。ReAct 是提示工程的一种,它通过设计 prompt 来让大模型输出更有帮助的结果。
它主要的内容是让 LLM 先写出想法,然后再由 LLM 采取行动,接着根据获得的反馈(观察),继续思考、采取行动或者结束。
在 ZeroShotAgent 中这部分的具体流程大概如下:
-
首先需要自定义工具
langchain.tools.BaseTool或者利用一些 LangChain 中现成的工具 -
由
initialize_agent等方法构建Agent时,会通过如下方式生成 prompt 的模板:在
prompt.py中定义了一些与 prompt 有关的常量1
2
3
4
5
6
7
8
9
10
11
12
13
14
15PREFIX = """Answer the following questions as best you can. You have access to the following tools:"""
FORMAT_INSTRUCTIONS = """Use the following format:
Question: the input question you must answer
Thought: you should always think about what to do
Action: the action to take, should be one of [{tool_names}]
Action Input: the input to the action
Observation: the result of the action
(this Thought/Action/Action Input/Observation can repeat N times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question"""
SUFFIX = """Begin!
Question: {input}
Thought:{agent_scratchpad}"""接着生成 prompt 的时候会把它们拼接起来,同时将工具的名称和描述信息加入 prompt:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
def create_prompt(
cls,
tools: Sequence[BaseTool],
prefix: str = PREFIX,
suffix: str = SUFFIX,
format_instructions: str = FORMAT_INSTRUCTIONS,
input_variables: Optional[List[str]] = None,
) -> PromptTemplate:
"""Create prompt in the style of the zero shot agent.
Args:
tools: List of tools the agent will have access to, used to format the
prompt.
prefix: String to put before the list of tools.
suffix: String to put after the list of tools.
input_variables: List of input variables the final prompt will expect.
Returns:
A PromptTemplate with the template assembled from the pieces here.
"""
tool_strings = "\n".join([f"{tool.name}: {tool.description}" for tool in tools])
tool_names = ", ".join([tool.name for tool in tools])
format_instructions = format_instructions.format(tool_names=tool_names)
template = "\n\n".join([prefix, tool_strings, format_instructions, suffix])
if input_variables is None:
input_variables = ["input", "agent_scratchpad"]
return PromptTemplate(template=template, input_variables=input_variables) -
接着用户输入,这部分内容是 input,然后由此生成 prompt 提供给 LLM,接着在 LLM 输出中包含停止词(
"\nObservation: "等)的时候将其截断,提取其中Action和Action Input两处中的内容,根据Action去匹配工具,将Action Input的内容提供给工具 -
接着将工具的返回信息接在
Observation:后面。接着将这整个新产生的内容接在变量agent_scratchpad后面。 -
然后再利用上面的 prompt 模板重新生成 prompt 提供给 LLM,由此继续,直到达到终止的判断条件(应该是没有被截断或者达到迭代次数上限)。
-
最后返回 LLM 最终的答案。
如果是先构建 LLMChain 再由此构建 Agent,那么在构建 LLM 的时候指定了 prompt 模板,再由 AgentExecutor.from_agent_and_tools 得到 AgentExecutor 的就能使用自己的 prompt 模板。