
有人读了论文然后用大白话讲出来真是好啊。李沐老师真是大好人。
GPT
GPT 模型的提出是为了在大量无标注数据但稀缺有标注数据的情况下能在 NLP 任务上取得更好的效果。它的想法是先在无标注文本上训练出一个语言模型,然后再对特定的下游任务进行微调。
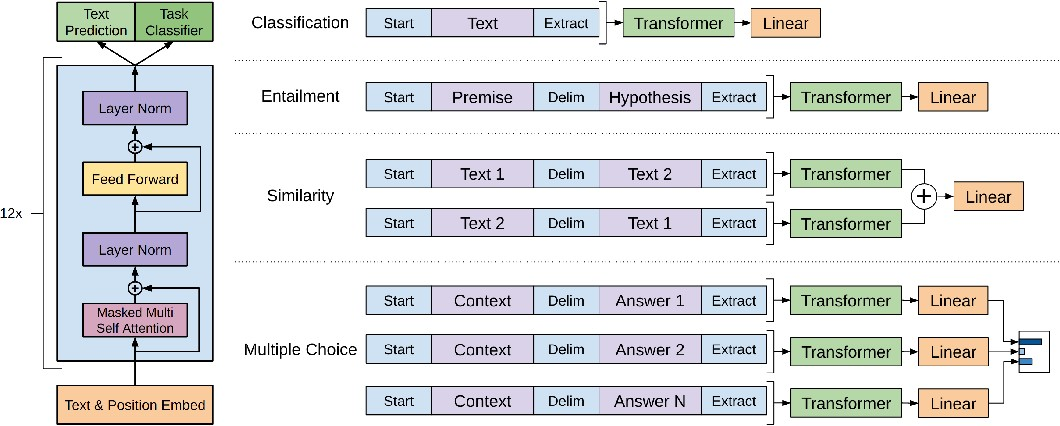
GPT 的架构使用 Transformer 解码器堆叠若干层,强调这里是解码器是因为解码器只能看到时间步 之前的信息,而编码器则会直接看到整个序列。
预训练 在无标注文本上训练模型最大的问题是不便于寻找损失函数,GPT 选择最大化根据每 个词预测下一个词的似然函数作为目标函数,其中 为上下文窗口的大小。 即最大化对数似然:
其中 表示这是 GPT 中第一个目标函数, 表示文本。
微调 假如接下来进行一个分类的任务,那么为 GPT 添加一个线性层然后再进行 softmax,定义 表示对于每组数据预测正确的概率的对数,这是第二个需要最大化的目标函数。实际将 和 稍微结合一下效果更佳,新设置超参数 ,令 作为最终的目标函数。
论文中介绍了 4 类自然语言处理任务的微调的细节:分类、蕴含(判断一句话是否蕴含另一句话)、相似性、多项选择题。其中 Start、Extract 和 Delim 都是特殊词元。这里最后线性层直接用 Extract 词元在经过 Transformer 变换得到的隐状态作为输入。
GPT-2
GPT-2 是在 BERT 模型发布之后再发布的。为了击败 BERT,作者用了百万级别的数据集、15 亿的参数(BERT large 为 3.4 亿)。军备竞赛,确信.jpg
在 GPT-2 中使用一个新的设定:zero-shot,意思是不使用任何有标号数据 ,这也意味着没有微调的过程。据说是因为光是增大模型和 BERT 相比提升很小,发一篇 paper 大家会觉得很没意思,于是换了一个更难的问题。
训练数据 来自 Reddit 中至少有 3 个 karma 的链接,有 3 个 karma 意味着还有些人觉得这个链接有帮助。这样与直接使用 Common Crawl 相比,数据质量有所提高。
预训练
- 词表使用 BPE 算法(Byte Pair Encoder,字节对编码),将每个词划分为出现频率较高的子词,以此来压缩词表大小,同时能更好地表示低频词。
- 训练的时候采用多任务训练的方式,所有的任务训练时共用 Transformer 参数,同时让输入的形式更像自然语言(任务描述,…),例如(translate to French, 输入, 输出)。但我没有太懂它是怎么把大量的无标注文本转化为有某个具体的任务描述的有标注的数据。
GPT-3
在 GPT-2 中发现 zero-shot 不是那么好做,但是于是由于 GPT-3 有 1750 亿可学习参数,使用梯度进行微调会导致计算代价非常高昂,不便于开发产品, GPT-3 对 zero-shot 的限制进行一些削弱,即情境学习(in-context learning)。它是指在被给定的几个任务示例或一个任务说明的情况下,模型应该能通过简单预测以补全任务中其他的实例。取决于给定的任务示例的数量,具体分为 few-shot、one-shot 和 zero-shot。
模型 与 GPT-2 类似,Transformer 块多叠几层,加宽,多头注意力的单个头的大小也增大,训练的批量大小也增大。但是这里的学习率下降。
训练数据 为了训练一个比 GPT-2 大 100 倍的模型,不得不重新考虑 Common Crawl,经管它的数据非常地脏。
- 首先将 Common Crawl 中的数据作为负例,GPT-2 使用的数据集作为正例,训练一个二分类器,然后保留 Common Crawl 中被分为正例的数据。
- 去重,如果两篇文章相似,那么我们把这篇文章去掉。具体使用了一个叫做 lsh[(Locality-Sensitive Hashing, 局部敏感哈希) 的算法,它的想法是把数据降维,使得相似的数据尽可能在降维后相近,由此来去重。
接着再将筛选过的 Common Crawl 和之前的高质量数据合并到一起作为 GPT-3 的训练数据。
其他一处有意思的内容是,GPT-3 计算量指数增加的时候,损失线性下降。
InstructGPT
chatgpt 基于 instructgpt,在标注数据上更多是对话形式的数据。
把模型更大,数据变多,并不意味着它能按照用户的想法去做事,有时候它能补全一个问题,有可能是因为数据中出现过,也有可能是生成一堆没有帮助的无关信息。所以接下来还是想办法去做微调去让模型更有帮助性、说更多的真话、有更好的无害性。但是之前声称只使用无标注数据和少量例子来学习,现在回到使用有标注数据集非常地打脸,所以 OpenAI 做后面的内容稍微包装了一下
训练的流程和数据
- 在 OpenAI 的 API 上收集到的各种问题以及由标注人员写的问题,让人去写答案,接着再用这些数据对 GPT-3 进行微调,得到的新模型称为 SFT(supervised fine-tuning,有监督微调)
- 让模型生成答案,然后人工去对这些答案排序,然后去训练一个奖励模型 RW(対生成的答案进行打分,使得相对顺序与人工排序尽量一致)
- 然后用得到的奖励模型通过强化学习去训练 SFT
由于生成式的标注比判别式的标注成本更高,因此有了第 2 步和第 3 步,否则做一个足够大的 SFT 数据集,后面两步有点多余了。
实际情况是由标注人员写一些问题,预训练了一个模型,作为测试版发布出来,让大家去玩,由此收集到了很多 prompt,接着利用这些 prompt 用来生成 3 个数据集:人工写答案的用于 SFT 的数据集、人工排序的用于奖励模型的数据集和最终的强化学习的数据集。
为了获得高质量的数据,所以 openai 直接招了一个 40 人的标注团队,以便能在几个月之间与他们进行合作。讲怎么招人这块,OpenAI 讲的超详细,反而技术细节越讲越简略。
模型
有监督微调 这一块和之前的 GPT 系列的微调差不多
奖励模型 模型具体的话直接把 SFT 中最后的 softmax 层去掉换成一个线性层输出一个数。这里发现用 175 B 参数的模型训练很不稳定,使用了一个缩小的模型。损失函数使用的是 Pairwise Ranking Loss,具体的话假如我们有一个输入 ,随机选取了两个回答 和 ,其中 比 更好,模型为它们分别打分为 和 ,那么此时的损失为 ,其中 为 Sigmoid 函数。 在整个数据集上的损失定义为在数据集中按一定分布选取 得到的损失的期望:
其实相当于去让一个排在前面的选项的分数比一个排在后面的选项的分数尽可能高,对于单个输入的多个选项,我们使得这 个分数差尽量都大一点,其中 为选项个数。
强化学习模型 现在我们训练好了一个用于打分的模型 RM,那么接下来的想法是去训练另一个模型 RL,它初始和 SFT 相同,接下来输入一个 ,用 RL 生成出一个 ,接着用 RM 去给 打分 ,我们去最大化得到的这个分数。
具体的话是最大化下面这样一个目标函数:
其中 为超参数,其中 表示从强化学习数据集中随机选取 ,然后用 RL 得到 ,这样算期望, 表示在 GPT-3 的预训练数据集中抽样。直接看个这个式子比较抽象,分三部分解释一下:
- 第一个是 这部分,这部分比较好理解,就是我需要去最大化的一个分数。
- 第二个是 后面带 的那一项,其中 表示把 扔进模型 RL 会生成 的概率。这一项是用于正则化的一项,目的是希望 RL 不要偏离 SFT 太多。
- 最后一个是从 中采样的那一项,这一项相当于语言自回归模型中的目标函数,旨在希望 RL 能保持语言模型一些基本的需要学习到的东西。
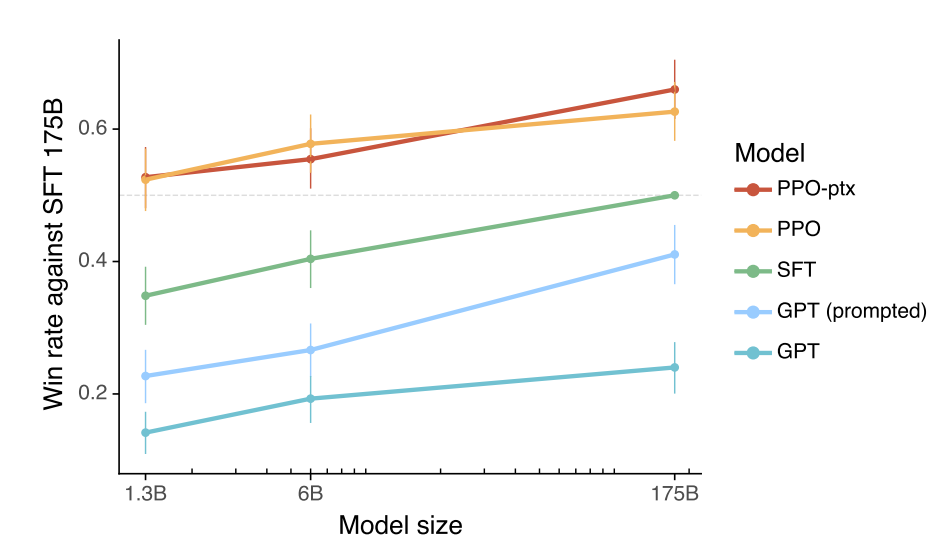
最终 InstructGPT 达到的效果大概是能用 GPT-3 的参数数量达到和 GPT-3 等同的效果。但其实 InstructGPT 做的优化仅去考虑了帮助性
GPT-4
GPT-4 是一个多模态的模型,相比之前的模型,它能允许使用图片作为输入的一部分,除此之外,各方面性能、安全性等相比 chatGPT 也有所提高。
训练过程
训练过程和 GPT-3 类似,加入了一些新的数据集,然后再进行 RLHF(Reinforcement learning with human feedback,通过人类反馈强化学习,也是 InstructGPT 中强化学习的那部分)。数据集具体有些啥,OpenAI 直接通过一段废话代过了,
预测训练效果
GPT-4 这样的大模型调超参数是一个很大的问题,在一个小模型上看参数效果,但由于小模型和大模型在泛化能力上差别过大,再将参数移到大模型上效果可能不佳。直接在大模型上跑参数,一是开销过大,而是等待时间也过长,完整训练一次就是以月为单位。
OpenAI 发现仅用 GPT-4 训练所需算力的万分之一,就已经可以根据得到的各周期的损失预测出最终的损失。
安全性
安全性通过两方面来提升
- 通过各领域专家来做测试
- 另一个是额外训练一个分类器,判断一个 prompt 是不是敏感的,不应该去回答的。
剩下感觉都是广告,啥都没写。
总结和吐槽
感觉 GPT 系列论文是真的一篇比一篇细节少,本来感觉 GPT-2 和 GPT-3 很多技术上的细节都没讲清楚,GPT-4 直接省略所有技术细节,论文通篇都是说自己有多强。“让我帮你省一点时间”

OpenAI (x),CloseAI(√)。75 页论文 74 页的废话
- 训练模型需要考虑安全性、合法性、有效性。当然,就我的破笔记本而言也训练不出什么有危险言论的模型,能输出一句正常的句子就谢天谢地了。
- 数据和训练方式也是机器学习中很重要的一环。所以别天天惦记着那逼模型了